Ship It
Nick Sivo and I are releasing Ship, an issue tracker for software projects.
We started with the premise that it should be a native app in recognition of how frequently it ought to be referenced when used properly. We then decided to design around these features that we are uniquely strong at:
- Offline support for creating, reading, querying, and updating issues
- Seamless file handling, with offline caching and resumable uploads and downloads
- Rich text editing and display, with embedded media and high fidelity copy and paste
- Flexible querying and charting
- Speed
Ship's name comes from this story about the release of the Macintosh, which I love because it's both inspirational and practical at the same time. With such an ambitious name, we had to press through and actually, you know, ship something. Here it is: https://www.realartists.com.
Preconceptions and Assumptions
This first version of Ship is built for people like us. Specifically, we want to track hundreds or thousands of issues and pull up something we filed two months ago as quickly and easily as something we filed two hours ago.
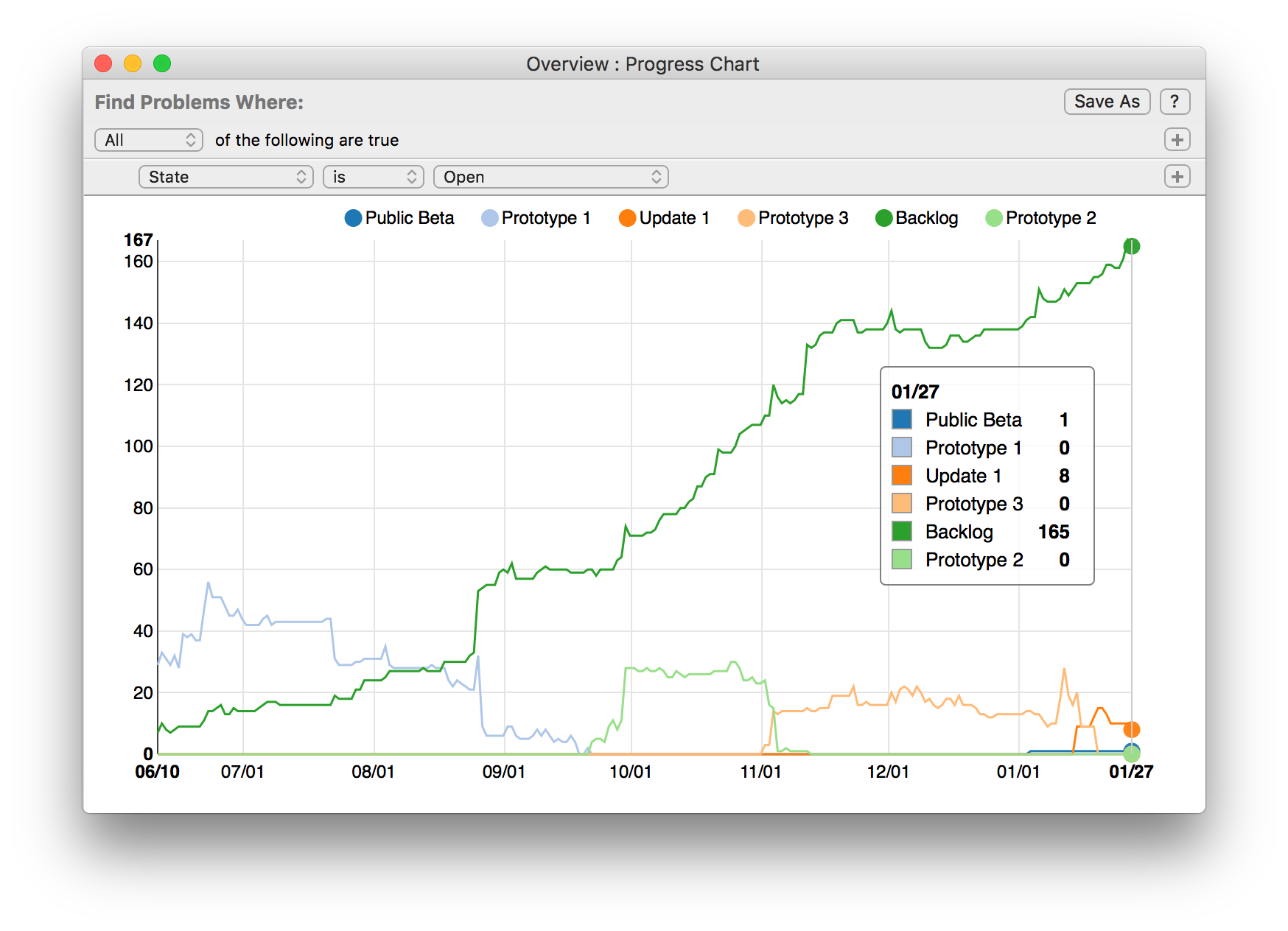
We want to reduce friction when filing all of those issues, but we also want some structure, grouping issues by classification into components with specific milestones. Having some structure makes issues easier to find and lets us visualize our progress and determine just how much we have to go.
For example:
We want to be able to quickly answer all sorts of questions with easily built queries. Here are some of my favorites:
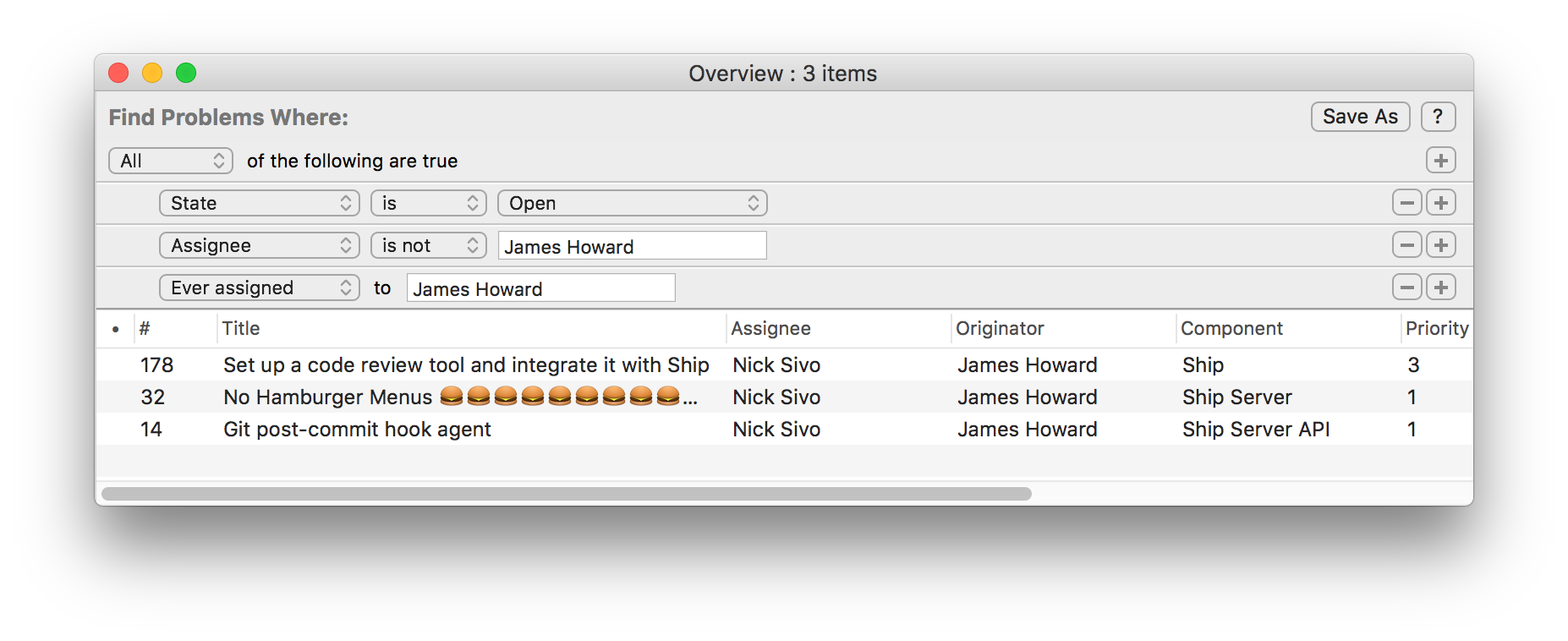
Not my problem (open issues that used to be assigned to me but no longer are):
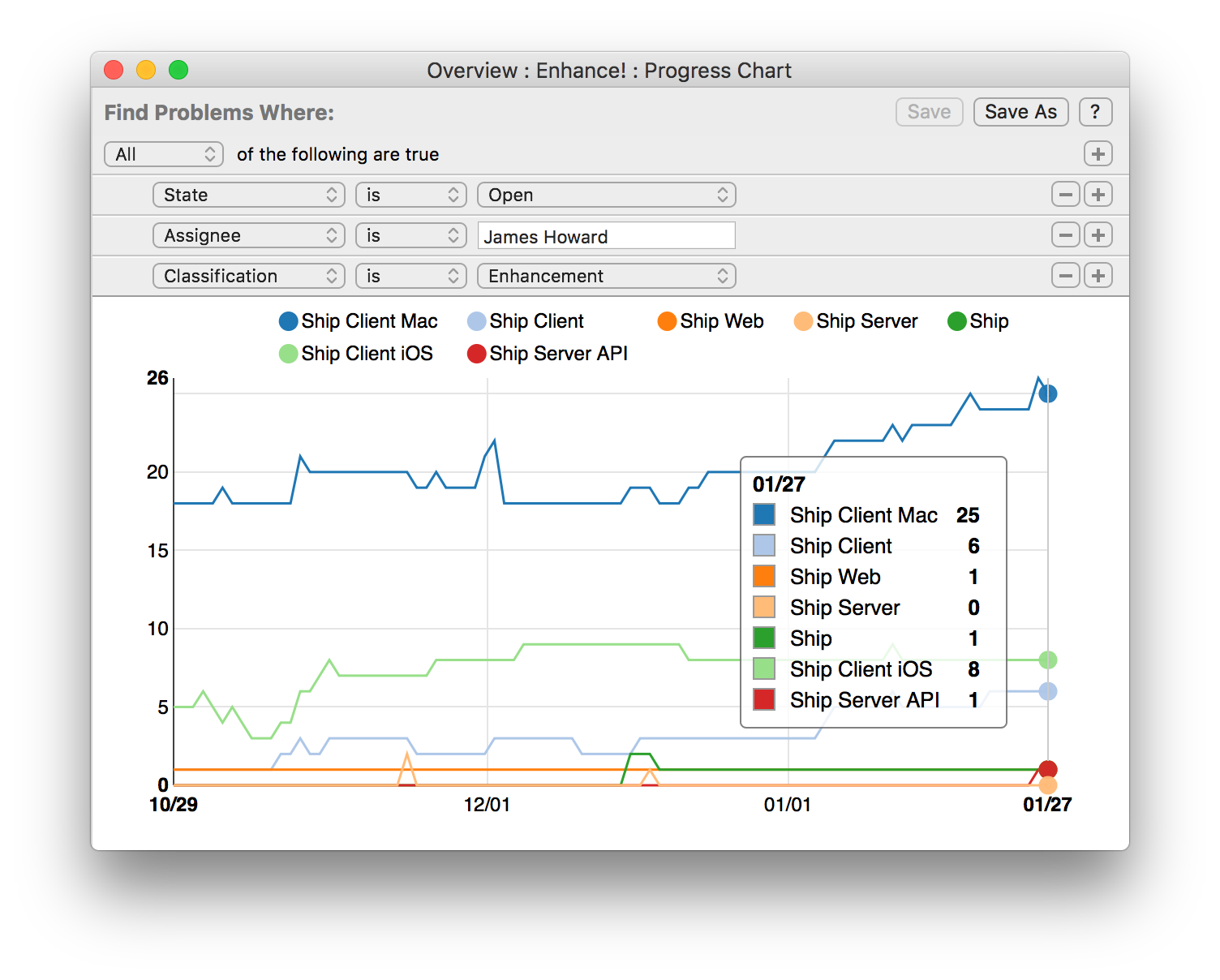
Enhance! (open enhancements assigned to me - got to stay on top of the little things):
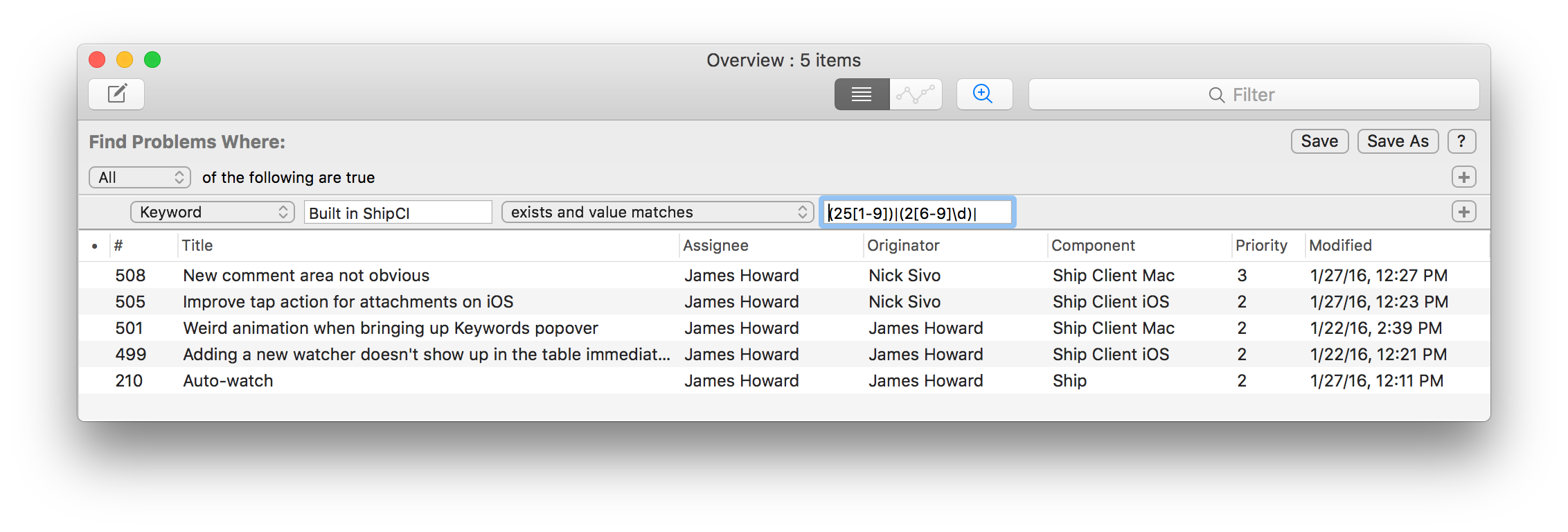
Changes built by the buildbot since build 250:
We also want a scriptable API to store relevant information from our other tools. For example, this is how our buildbot tags issues that are fixed in each of our builds:
api = shippy.Api(token=args.apitoken)
identifiers = set()
for commit in commits:
identifiers.update(locate_fixed_problems(commit.message))
for id in identifiers:
api.problem_keyword_set(id, "Built in %s" % (args.bot), args.build)
Technical Notes
We decided to build Ship with proper bidirectional offline support from day zero, enabling some unique and powerful features. From a technical standpoint it sets Ship apart from online-only issue tracking systems. Because of that, I thought I'd highlight some interesting tidbits about how we implemented our offline support. I'll start with the database schema and queries, explain how offline edits are handled, and cover file attachments and historical snapshots.
At a high level, data in Ship is represented as a log. Everything you do is a log entry. Every attribute of an issue you file is just a log entry, and every issue is itself just the sequence of those entries. Here's what it looks like in JSON:
{
"identifier": "39d11394-8d44-4662-b418-75d4bb0c1543",
"problemIdentifier": 501,
"authorIdentifier": "27a1cb73-36cb-4573-8edf-be0adc9b9f54",
"creationDate": "2016-01-22T21:04:46.23Z",
"sequence": 35092,
"batchIdentifier": "0f0bb8bf-a670-47d0-a796-ca550f88ba71",
"type": "state",
"stateIdentifier": "93a067fe-011f-4cca-9fa2-00aa18d38d85"
},
{
"identifier": "7862b8f6-d038-4e31-ae23-2e3bfc8e162c",
"problemIdentifier": 501,
"authorIdentifier": "27a1cb73-36cb-4573-8edf-be0adc9b9f54",
"creationDate": "2016-01-22T21:04:46.23Z",
"sequence": 35093,
"batchIdentifier": "0f0bb8bf-a670-47d0-a796-ca550f88ba71",
"type": "title",
"title": "Weird animation when bringing up Keywords popover"
}
Every time a client connects to the server, it informs the server of its latest log entry sequence number. The server then compresses and sends all of the entries that have been created since the client's last connection. Further, the connection remains open, and new changes are streamed to all connected clients.
On both the client and the server, the log is stored in a single database table (one row per entry). Flattened representations of the issues are stored in an additional table, where the data is computed by rolling up the log on a per issue basis (one row per issue). This flattened representation enables fast and efficient querying.
Database Schema and Queries
One interesting aspect of the client / server design is that both the client and the server use essentially the same core database schema and contain the same data. This means that at a high level, a single query makes sense to run against both the client database and the server database. While initially only the client supported querying, as we built our REST and Python APIs we found ourselves wanting to run both ad hoc and user saved queries against the server.
The clients use NSPredicate to perform queries against their Core Data stores. This is done for two reasons: the Mac client uses a heavily customized NSPredicateEditor to good effect to allow people to interactively build queries, and second how else are you going to query Core Data?
The server side is an ASP.NET app backed by SQL Server. We wrote a C# library that can parse NSPredicate formatted queries and convert them into LINQ expression trees that we can run with Entity Framework on the server. I'm guessing the set of people who have a bunch of NSPredicate defined queries that they also want to run in .NET land is probably just Nick and I, but it's still a neat technical achievement.
NSPredicate is also nice in that it gives us a lingua franca for doing queries. A lot of issue trackers invent their own query language, and I feel like that's a mistake. Almost nobody except the people who work on it are going to remember some issue tracker specific query language. NSPredicate is nice because it's easily composed and decomposed to and from a visual query builder (unlike SQL) which is what most users will want to use, and if you do drop down and actually write NSPredicates directly, as our API allows you to do, at least some set of users are already fluent with the query language.
Offline Edits
What I've described so far should give you the picture of how read support in offline mode works in the Ship client. The client maintains its own complete mirror of the server's database, and the server live syncs changes down to it whenever the client is online.
But what if you want to file a new issue or edit an existing issue while offline? In these cases, the client updates its local database with the corresponding pending log entries. When you go back online, the client attempts to sync those pending changes back to the server, and most of the time succeeds.
However, in some cases, your changes might conflict with changes made by somebody else. When that happens, we fork the issue (just like git) and show a really nice merge conflicts UI that allows you to resolve the conflicts. Because we know exactly where in the log pending changes were applied, we can ensure we only conflict in the case that two people make logically simultaneous and mutually exclusive edits (e.g. you change the priority from 1 to 2 and I change it from 1 to 3 without knowing about your change). Our merge support is probably overkill since a lot of popular tools choose the data loss route in this case, but data loss bugs me so much that we had to do the right thing.
File Attachments
You can add files of arbitrary type and size inline in Ship. Storing and syncing complete bug databases for organizations on client machines for offline use is not actually that crazy. Even tens of thousands of issues don't require a that much storage if you ignore attachments.
Whereas clients have full databases in terms of their ability to create, view, and query issues offline, we can't reasonably store all of the attachments offline. I mean, just counting Rob Ford gifs alone, I probably add more attachments than Nick would want to store on his computer. Instead, we optimistically download tiny attachments, caching them with a reasonably long lifespan. Bigger attachments are lazily downloaded and cached with a short lifespan, or when possible for supported media files, streamed on demand with no local caching.
On the server side the attachments get stored in Azure blob storage. The process of uploading attachments is basically memory map the file to be uploaded, and then send checksummed and optionally deflated 4MB chunks up to the server until the file is fully uploaded. Since we're operating only on relatively small chunks at a time, if we get interrupted due to network conditions or the laptop going to sleep or whatever, we can just pick up where we left off at the next opportunity.
We also use a kind of neat approach for compressing the chunks to upload. We try to use zlib to compress the chunks as we upload, and if we get an improvement then great. If we fail to improve the chunk size by some factor, we mark it as a failure and move on to the next chunk. If we get a certain number of failures (4), we assume the data we're uploading is already compressed and then stop trying to compress any more. This heuristic works well and allows us to really quickly upload large log files and the like which are highly compressible while not wasting cpu cycles in zlib on, say, mp4 screencasts.
One last cool thing we do is we let other connected clients observe upload progress of attachments over the web socket. So suppose Nick is attaching a large log file to an issue, from my computer I can actually see that the attachment is on its way and I can ask to download it as it becomes available.
Historical Snapshots
Ship has a flexible progress charting system built into it. You can use it to see your incoming and outgoing issue rates, compare progress across milestones, teams, and team members. You can see if you're speeding up or slowing down, getting buried or digging out.
To support these charting features, as well as a few other querying features in Ship, it is possible to query for issues not just as they are in the present, but as they were at a specific point in time or range of times in the past.
It turns out that this is actually fairly straightforward with the log format used by Ship. By simply taking subsequences of the sequence of log entries for a given issue at the committed save points (i.e. points where somebody saved an issue), we can produce all of the logical historical states of the issue. We just save those rolled up historical states into a table in the database with some validity date ranges attached and we're ready to query against it for charting or various questions you might want to ask (e.g. show me all open issues that were ever assigned to me, but now are re-assigned to somebody else).
Wrap Up
If you've read this far, or just scrolled to the end, you should check out our demo.
After you try it out, please get in touch, we would like to hear from you.